|
Abbiamo trattato la comunicazione fra molto processi in MPI e abbiamo esaminato il caso di studio del TSP affrontato con un algoritmo genetico sia con comunicazione sincrona che asincrona. Da notare la differenza di prestazioni che risultano essere migliori nel caso asincrono. L'immagine si riferisce a due bravi run sui 30 nodi del cluster delle due istanze del programma quello con comunicazione asincrona (a sinistra) e quello con comunicazione sincrona(a destra). Notate come la CPU sia meglio utilizzata nel primo caso. Il processo era diviso in più thread su ciascun nodo tramite OpenMP. 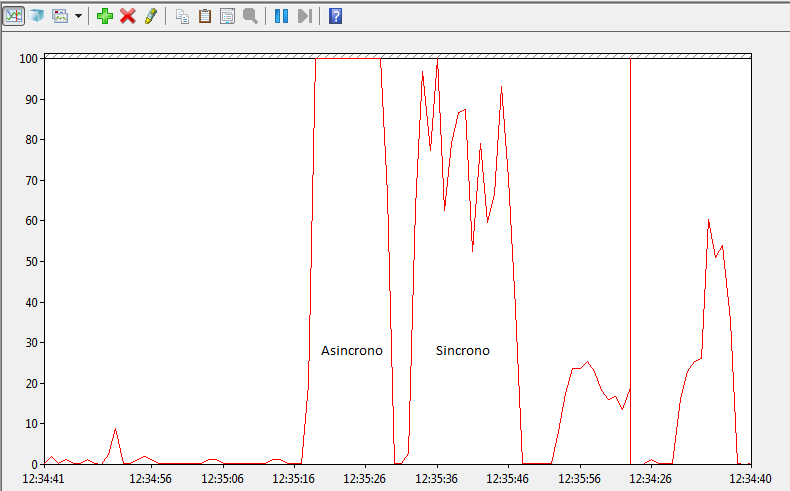
Sono stati trattate le chiamate MPI_Test eMPI_Probe ( vedi lezioni dello scorso anno )
Sono state presentate le librerie BOOST_MPI Sono state trattate le operazioni RMA con le chiamate: MPI_Comm_split(MPI_COMM_WORLD,my_id<=1,my_id,&com); MPI_Win_create(&receiveb,sizeof(int),sizeof(int),MPI_INFO_NULL,com,&pwin); MPI_Put(&sendb,1,MPI_INT,dest,0,1,MPI_INT,pwin); MPI_Get(&getb,1,MPI_INT,dest,0,1,MPI_INT,pwin); MPI_Win_fence(0,pwin); MPI_Win_free(&pwin); Sono stati trattati gli argomenti:
BOOST_MPI, Mpi_probe e Mpi_test ( vedi lezioni dello scorso anno ). E le operazioni RMA (Il codice completo lo trovate in fondo al post ) MPI_Win_create(&receiveb,sizeof(int),sizeof(int),MPI_INFO_NULL,com,&pwin); MPI_Get(&getb,1,MPI_INT,dest,0,1,MPI_INT,pwin); MPI_Put(&sendb,1,MPI_INT,dest,0,1,MPI_INT,pwin); MPI_Win_fence(0,pwin); MPI_Win_free(&pwin); In queste lezioni abbiamo visto come usare bene la cache sia importante anche in ambito parallelo e abbiamo introdotto lo standard OpenMP. Nella immagine che segue vedete il flag di compilazione da impostare in Visual Studio per permettere l'uso di OpenMP. 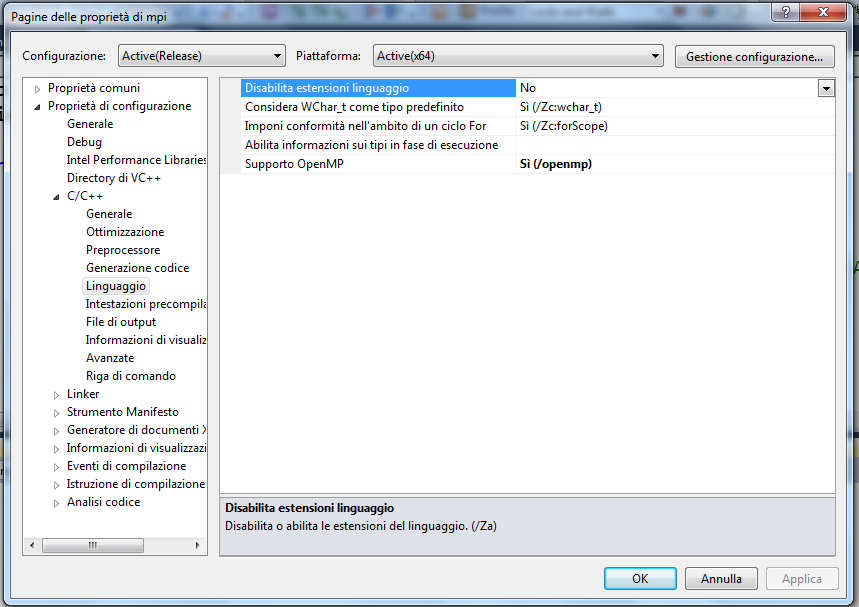 Il programma mostrato durante Martedì 13 mostrava un pessimo load balancing. Il grafico che segue mostra l'occupazione del processore durante l'esecuzione. 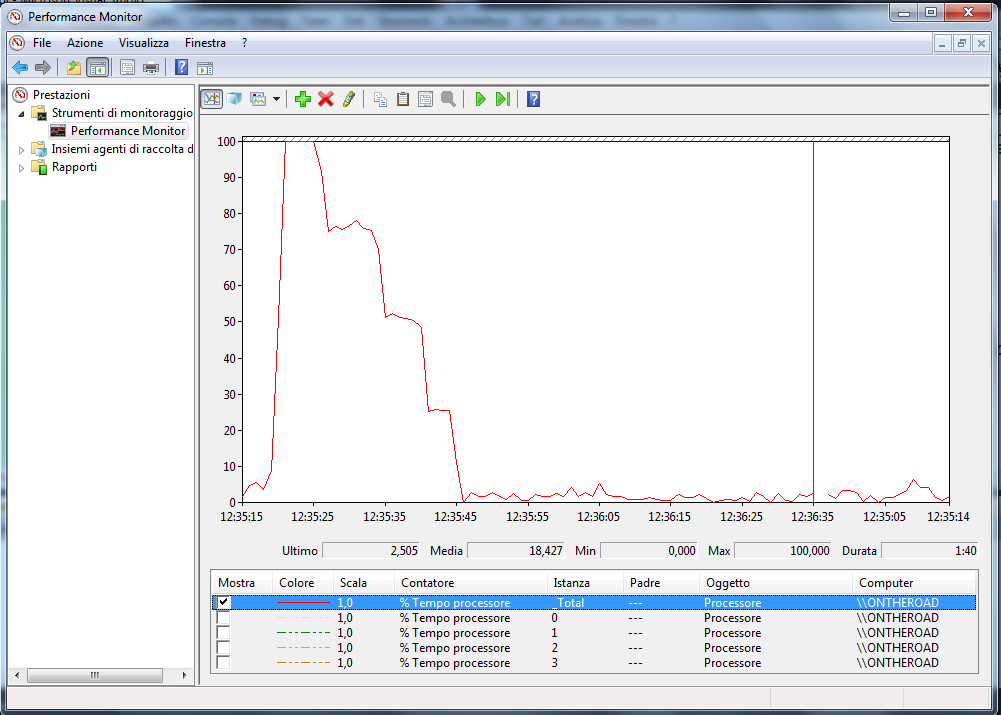 Aggiungendo uno uno schedule dynamic al ciclo for del programma di esempio si ottiene un grafico di carico molto più equilibrato. Da notare anche la minor durata del processo. 18.8sec contro 24.8 nelle prove fatte in aula. 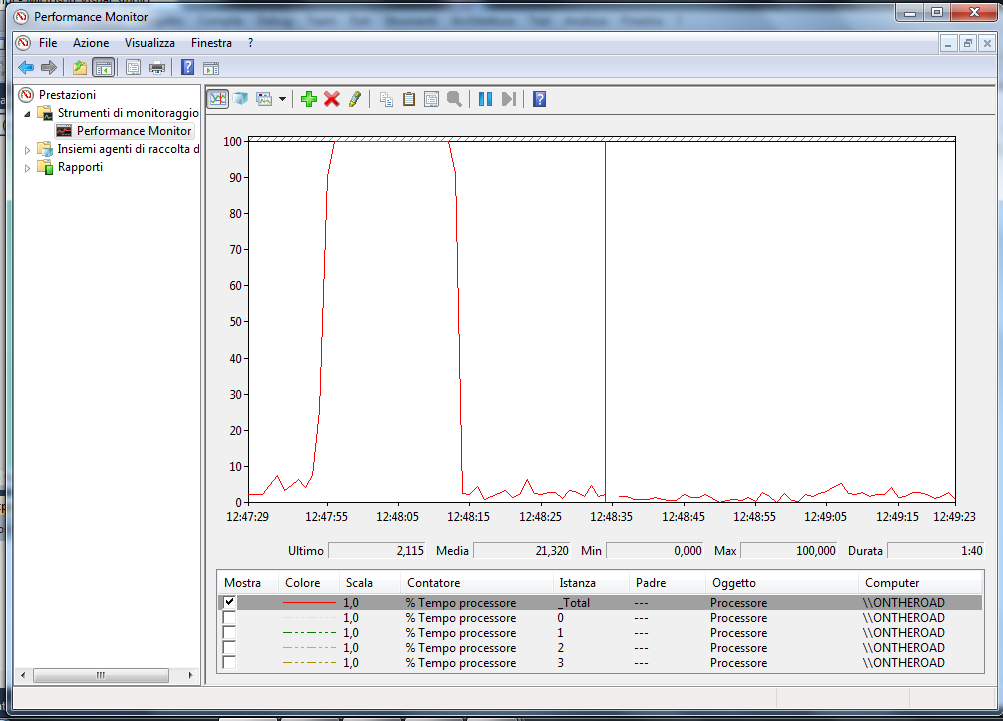 Il file con il programma dimostrativo si trova qui:
Abbiamo illustrato l'uso delle BOOST THREAD e delle Espressioni Lambda . Il codice illustra anche il problema del FALSE SHARING. Si veda ( tra i molti ) per esempio questo articolo:http://www.codeproject.com/Articles/51553/Concurrency-Hazards-False-Sharing
E' iniziato il nuovo corso e alcuni argomenti sono stati introdotti.
Da guardare subito .... le librerie BOOST THREAD . Attendendo una sistemazione migliore abbiamo parlato di comunicazioni collettive in MPI.
Inoltre è stato presentato ai primi di maggio un piccolo programma che implementa un algoritmo genetico. Ve lo lascio come esercizio da parallelizzare . Chiaramente è solo un piccolo esempio diadttico. E inoltre..... cominciate a pensare su come potrebbe essere possibile parallelizzare il Crivello di Eratostene per trovare i numeri primi: #define MAX_PRIME 100 int main(int argc, char* argv[]) { int prime[MAX_PRIME]; for(int i=0; i<MAX_PRIME; i++) prime[i]=0; // inizializzazione for (int i=2; i<MAX_PRIME; i++) for (int j=i*i; j<MAX_PRIME; j+=i) prime[j]=1; for(int i=1; i<MAX_PRIME; i++) if (prime[i]==0) cout << i << endl; // STAMPA } Presentazione di alcuni concetti di I/O parallelo. In particolare abbiamo scritto e letto un file in modo non contiguo usando un datatype appositamente creato.
#define BUFSIZ 12 #define INTS_PER_BLK 3 int main(int argc, char* argv[]) { int my_id, numprocs,length; int sendb[BUFSIZ],receiveb[BUFSIZ]; MPI_Status status; MPI_File ilfile; MPI_Datatype filetype; [...]; MPI_File_open(com,"Test",MPI_MODE_CREATE|MPI_MODE_RDWR,MPI_INFO_NULL, &ilfile); // Quante righe 4, di quanti interi 3 , di quanto spaziate 3*numprocs MPI_Type_vector(BUFSIZ/INTS_PER_BLK,INTS_PER_BLK,INTS_PER_BLK*numprocs,MPI_INT,&filetype); for (int i=0;i<BUFSIZ;i++) sendb[i]=i+1000*my_id; MPI_File_set_view(ilfile,INTS_PER_BLK*my_id*sizeof(int),MPI_INT,filetype,"native",MPI_INFO_NULL); MPI_File_write_all(ilfile,sendb,BUFSIZ,MPI_INT,&status); MPI_Barrier(com); Notare come settando una view diversa il file venga letto in modo sequenziale. MPI_File_set_view(ilfile,BUFSIZ*my_id*sizeof(int),MPI_INT,MPI_INT,"native",MPI_INFO_NULL); MPI_File_read_all(ilfile,receiveb,BUFSIZ,MPI_INT,&status);I file con i programmi presentati sono scaricabili:Programma 1. Programma 2. |
AuthorGiuseppe Levi Archives
January 2015
Categories |
||||
 RSS Feed
RSS Feed
